1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
| const fs=require('fs-extra')
const path=require('path')
const yaml=require('js-yaml')
function parseArticle(article){
const match = article.match(/^---\n([\s\S]*?)\n---/);
if (match) {
try{
const frontMatter = yaml.load(match[1]);
const body = article.slice(match[0].length).trim();
return {frontMatter,body}
} catch (error) {
console.warn('Front Matter parse failed')
}
}
return { frontMatter: {}, body: article }
}
function convertContent(content, filePath, knowledgeDir){
let result = content;
result = result.replace(/\[\[.*?\]\]/g, '');
result = result.replace(/\[.*?\]\(.*?\.md\)/g, '');
const relativePath = path.relative(knowledgeDir, path.dirname(filePath));
const depth = relativePath.split(path.sep).filter(Boolean).length;
const upDir = depth > 0 ? '../'.repeat(depth) + '../' : '../';
result = result.replace(
new RegExp(`!\\[(.*?)\\]\\(${upDir}private_images/(.*?)\\)`, 'g'),
''
);
return result;
}
function extractImageName(content){
const matches = [];
const regex = /!\[.*?\]\(\.\.\/images\/(.*?)\)/g;
let match;
while((match = regex.exec(content)) !== null){
matches.push(match[1]);
}
return [...new Set(matches)];
}
async function ProcessSingleArticle(filePath, knowledgeDir, postsDir, knowledgeImagesDir, blogImagesDir){
const content = await fs.readFile(filePath, 'utf8');
const { frontMatter, body } = parseArticle(content);
if (frontMatter.published !== true) {
return false;
}
let processed = convertContent(body, filePath, knowledgeDir);
const finalContent = `---\n${yaml.dump(frontMatter)}---\n${processed}`;
const fileName = path.basename(filePath);
const targetPath = path.join(postsDir, fileName);
let needsUpdate = true;
if (await fs.pathExists(targetPath)) {
const existing = await fs.readFile(targetPath, 'utf8');
if (existing === finalContent) {
needsUpdate = false;
}
}
if (needsUpdate) {
console.log(`[+] updating: ${fileName}`);
const usedImages = extractImageName(processed);
for (const imgName of usedImages) {
const sourceImg = path.join(knowledgeImagesDir, imgName);
const targetImg = path.join(blogImagesDir, imgName);
if (await fs.pathExists(sourceImg)) {
await fs.copy(sourceImg, targetImg, { overwrite: true });
console.log(`[+] copied picture: ${imgName}`);
}
}
await fs.writeFile(targetPath, finalContent);
console.log(`[+] updated ${fileName} successfully`);
}
return needsUpdate;
}
async function getAllMdFiles(dir){
let fileList = [];
const items = await fs.readdir(dir, { withFileTypes: true });
for (const item of items) {
const fullPath = path.join(dir, item.name);
if (item.isDirectory() && item.name !== 'images') {
await getAllMdFiles(fullPath, fileList);
} else if (item.isFile() && item.name.endsWith('.md')) {
fileList.push(fullPath);
}
}
return fileList;
}
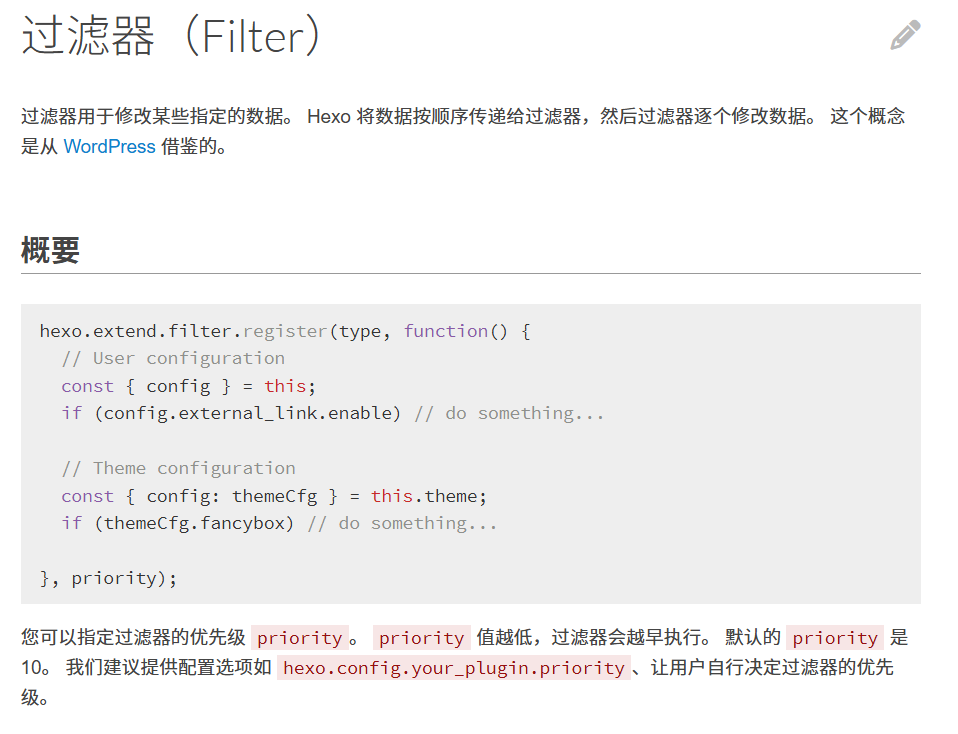
hexo.extend.filter.register('after_init', async function(){
const sourceDir = hexo.source_dir;
const knowledgeDir = path.join(sourceDir, 'myknowledge');
const postsDir = path.join(sourceDir, '_posts');
const knowledgeImagesDir = path.join(sourceDir, 'private_images');
const blogImagesDir = path.join(sourceDir, 'images');
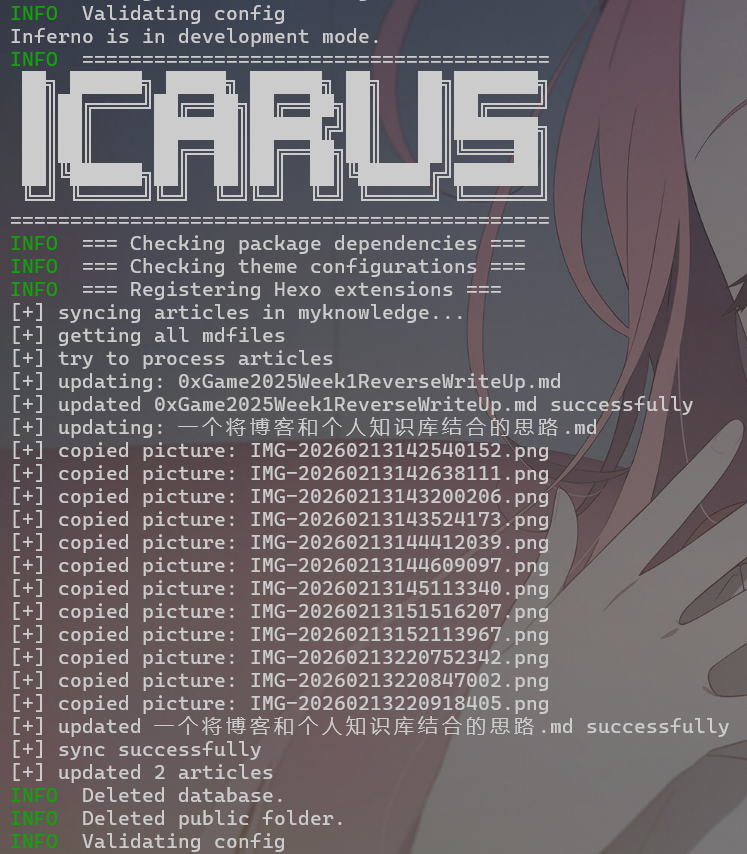
console.log('[+] syncing articles in myknowledge...');
await fs.ensureDir(postsDir);
await fs.ensureDir(blogImagesDir);
console.log("[+] getting all mdfiles");
const files = await getAllMdFiles(knowledgeDir);
let updatedCount = 0;
console.log("[+] try to process articles");
for(const file of files){
try{
const updated = await ProcessSingleArticle(
file,
knowledgeDir,
postsDir,
knowledgeImagesDir,
blogImagesDir
);
if(updated){
updatedCount++;
}
} catch(error){
console.error(`process failed ${file}:`,error.message);
}
}
console.log("[+] sync successfully")
if(updatedCount > 0){
console.log(`[+] updated ${updatedCount} articles`)
}
});
|