Re:从0到1的脚本之路
python脚本做题记录
[SWPUCTF 2021 新生赛]fakebase
1 | |
代码中,把flag逐字符转化为二进制,截掉前缀,填充为8位,再拼接这些二进制数得到tmp
然后把tmp转化为十进制b1,不断除31,同时用余数做S_box索引,把索引值拼接得到S
所以,解密思路是,首先,还原b1:
- b1利用后得到一系列索引值,所以由索引值反推b1
- 逆序s对照s_box得出索引(为了从最后一个余数开始还原b1)并组成一个列表。因为循环终止条件是b1//31==0,所以最后一次除只利用了商等于0,而余数未知,于是从0-30假设被弃掉的余数,枚举各种可能。
而如何判断哪种可能是我们需要的呢?就需要还原出flag并判断。把还原出来的b1转二进制,去掉前缀,填充到8的倍数方便截取二进制数,然后8个8个还原出字符,最后判断是不是flag就行了。
EXP:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26buf="u#k4ggia61egegzjuqz12jhfspfkay"
s_box = 'qwertyuiopasdfghjkzxcvb123456#$'
index_list=[]
#求索引值列表
for i in buf[::-1]:
for j in range(len(s_box)):
if i == s_box[j]:
index_list.append(j)
#print(index_list)
#枚举达到终止条件时的余数
for i in range(31):
#开始还原b1
b1=i
for j in range(len(buf)):
b1=b1*31+index_list[j]#不断加余数,乘31
tmp=str(bin(b1)[2:])#加密流程是把tmp从2进制转10进制,这里就反着来,把b1从10进制转2进制,截去前缀
tmp=tmp.zfill((len(tmp)//8+1)*8)#加密时字符转成8位2进制数,反着来就是把8位2进制数转为字符,所以先把tmp 8位对齐方便后续截取
flag=''
for i in range(0,len(tmp),8):
flag+=chr(int(tmp[i:i+8],2))
if 'NSSCTF' in flag:
print(flag)
#flag = "NSSCTF{WHAt_BASe31}"
[SWPUCTF 2021 新生赛]非常简单的逻辑题
题目给的代码如下:
1
2
3
4
5
6
7
8
9flag = 'xxxxxxxxxxxxxxxxxxxxx'
s = 'wesyvbniazxchjko1973652048@$+-&*<>'
result = ''
for i in range(len(flag)):
s1 = ord(flag[i])//17
s2 = ord(flag[i])%17
result += s[(s1+i)%34]+s[-(s2+i+1)%34]
print(result)
# result = 'v0b9n1nkajz@j0c4jjo3oi1h1i937b395i5y5e0e$i'加密思路是:逐字符取flag,通过//和%操作得到两个值s1和s2,把这两个值处理后,作为索引在s中索引出字符,拼接得到result
逆着来应该是把result错位分开,分成和s1有关的与和s2有关的,然后求出索引值,逆两个取余过程得到s1和s2,再把s1和s2运算得到flag字符
很显然,这个过程十分复杂,因为涉及取模的还原
所以考虑顺着加密的思路走,从常见的字符十进制值枚举,遇到加密后结果和result一样的就拿来拼接flag
EXP:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24s = 'wesyvbniazxchjko1973652048@$+-&*<>'
result = 'v0b9n1nkajz@j0c4jjo3oi1h1i937b395i5y5e0e$i'
tmp=''
flag=''
#提取出result里和s1、s2相关的字符
s1_list=[]
s2_list=[]
for i in range(0,len(result),2):
s1_list.append(result[i])
s2_list.append(result[i+1])
#开始爆破
#先求出加密过程两个索引值
for i in range(len(s1_list)):
index1=s.index(s1_list[i])
index2=s.index(s2_list[i])
#以索引值为判断条件,在常见字符的范围内重现加密过程,加密结果和索引值一致即为flag的字符
for j in range(33,126):
s1=j//17
s2=j%17
if (s1 + i) % 34==index1 and -(s2 + i + 1) % 34==index2:
flag+=chr(j)
break
print(flag)
#flag = "NSSCTF{Fake_RERE_QAQ}""
[SWPUCTF 2021 新生赛]re2
IDA打开,代码如下:
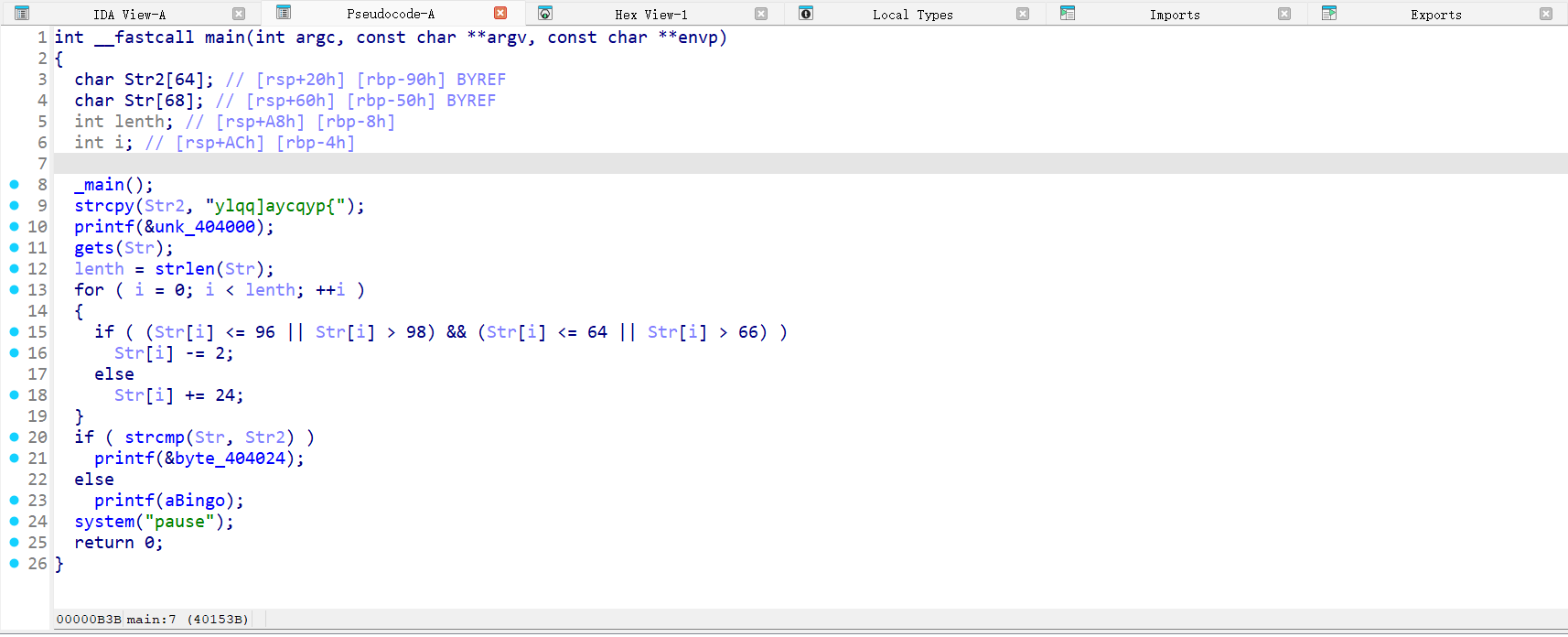
简单的字符处理,先判断字符是否在范围内,然后采用不同处理方式
直接正向利用代码,省点脑子。
EXP:
1
2
3
4
5
6
7
8
9
10
11
12
13alpha='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890{}-_'
dic={}
str='ylqq]aycqyp{'
flag=''
for i in alpha:
if (ord(i)<=96 or ord(i)>98) and (ord(i)<=64 or ord(i)>66):
dic[chr(ord(i)-2)]=i
else:
dic[chr(ord(i)+24)]=i
for i in str:
flag+=dic[i]
print(flag)
#flag = 'NSSCTF{nss_caesar}'直接得出来的结果是{nss_c{es{r},显然不对,猜测对应关系不唯一。打印出alpha经过处理后的结果,发现’{‘和’a’都对应’y’,所以把显然不对劲的两个’ { ‘改成’ a ‘
[WUSTCTF 2020]level1
附件给了ELF文件和一个txt,反汇编代码如下:
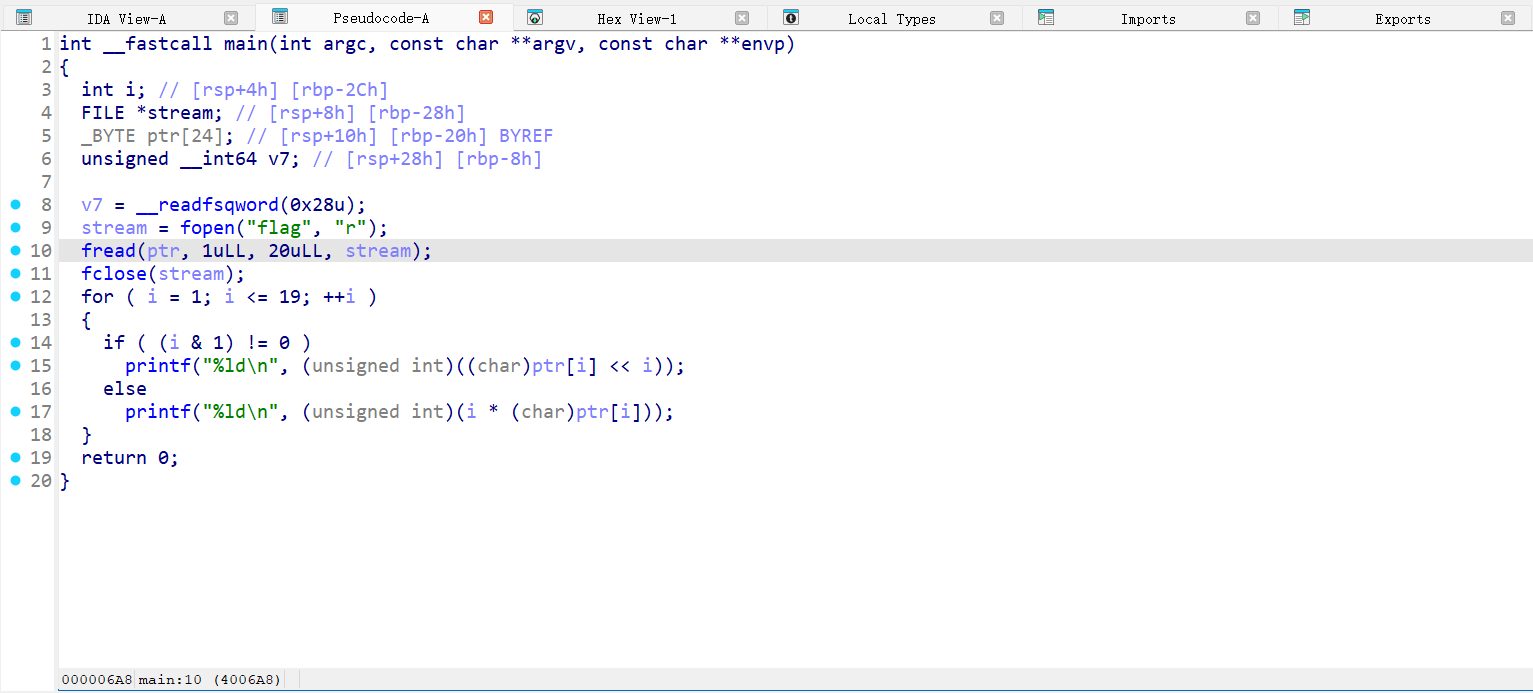
逻辑就是从flag文件里读数据,然后存到ptr里。后面是简单的可逆处理,但是要注意ptr是从下标1开始用的。给的txt应该就是处理后的结果,把它转成一个列表,第一位随便填一个数。然后逆。
EXP:
1
2
3
4
5
6
7
8
9output=[0, 198, 232, 816, 200, 1536, 300, 6144, 984, 51200, 570, 92160, 1200, 565248, 756, 1474560, 800, 6291456, 1782, 65536000]
flag=''
for i in range(1,len(output)):
if (i&1)!=0:
flag+=chr(output[i]>>i)
else:
flag+=chr(output[i]//i)
print(flag)
#flag = 'NSSCTF{d9-dE6-20c}'(改了前缀)
[SWPUCTF 2021 新生赛]简简单单的解密
给的python代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import base64,urllib.parse
key = "HereIsFlagggg"
flag = "xxxxxxxxxxxxxxxxxxx"
s_box = list(range(256))
j = 0
for i in range(256):
j = (j + s_box[i] + ord(key[i % len(key)])) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
res = []
i = j = 0
for s in flag:
i = (i + 1) % 256
j = (j + s_box[i]) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
t = (s_box[i] + s_box[j]) % 256
k = s_box[t]
res.append(chr(ord(s) ^ k))
cipher = "".join(res)
crypt = (str(base64.b64encode(cipher.encode('utf-8')), 'utf-8'))
enc = str(base64.b64decode(crypt),'utf-8')
enc = urllib.parse.quote(enc)
print(enc)
# enc = %C2%A6n%C2%87Y%1Ag%3F%C2%A01.%C2%9C%C3%B7%C3%8A%02%C3%80%C2%92W%C3%8C%C3%BA采用的加密算法是标准RC4,加密两遍恢复明文。最后面的调用base的两行经过调试发现相互抵消,所以整个逻辑就是先RC4加密,然后用urllib.parse.quote()方法编码,编码部分用原库自带的urllib.parse.unquote()就行了
EXP:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import urllib.parse
enc = '%C2%A6n%C2%87Y%1Ag%3F%C2%A01.%C2%9C%C3%B7%C3%8A%02%C3%80%C2%92W%C3%8C%C3%BA'
buf=urllib.parse.unquote(enc)
result=[]
for i in buf:
result.append(i)
key = "HereIsFlagggg"
flag = ''
def RC4(flag):
s_box = list(range(256))
j = 0
for i in range(256):
j = (j + s_box[i] + ord(key[i % len(key)])) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
res = []
i = j = 0
for s in flag:
i = (i + 1) % 256
j = (j + s_box[i]) % 256
s_box[i], s_box[j] = s_box[j], s_box[i]
t = (s_box[i] + s_box[j]) % 256
k = s_box[t]
res.append(chr(ord(s) ^ k))
cipher = "".join(res)
return cipher
flag+=RC4(result)
print(flag)
# flag = 'NSSCTF{REAL_EZ_RC4}'
[LitCTF 2023]ez_XOR
IDA打开,如图
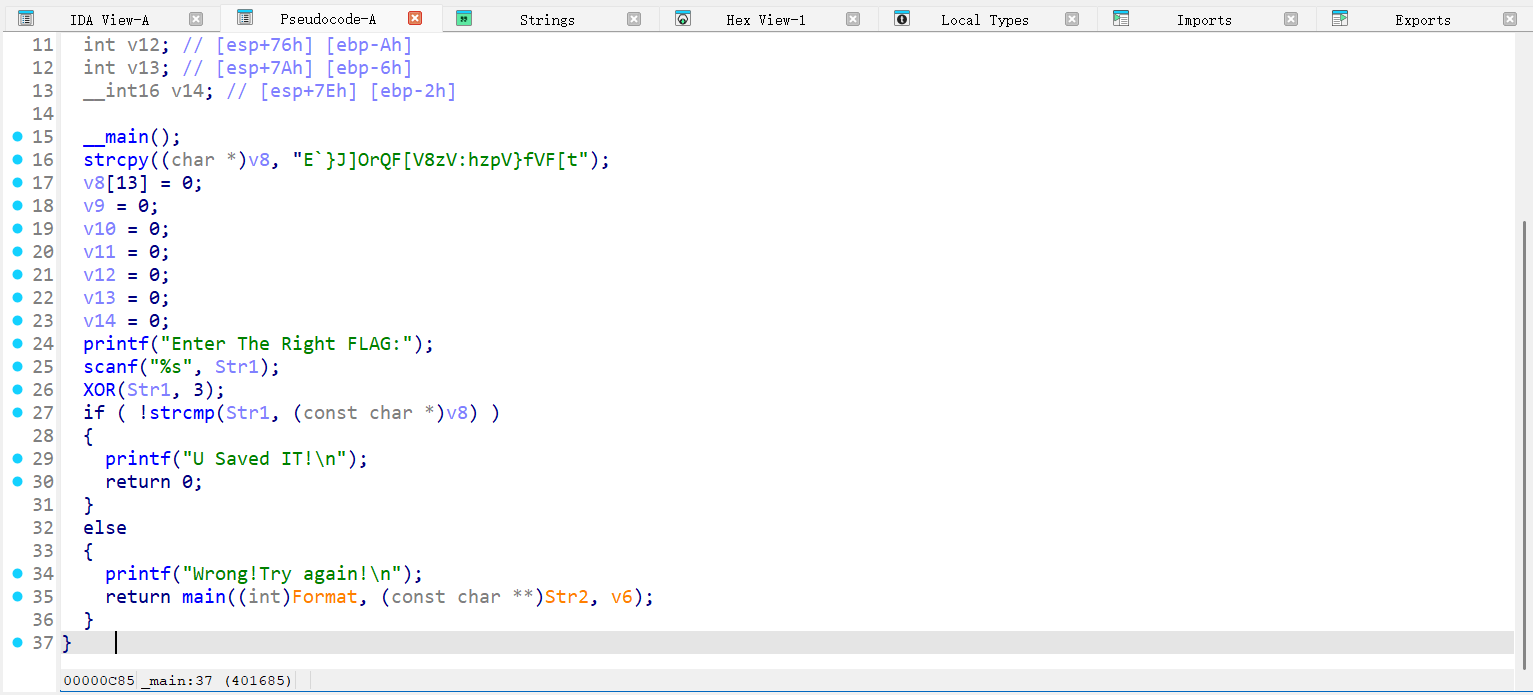
用XOR函数对输入做处理后,与str比较。打开XOR:
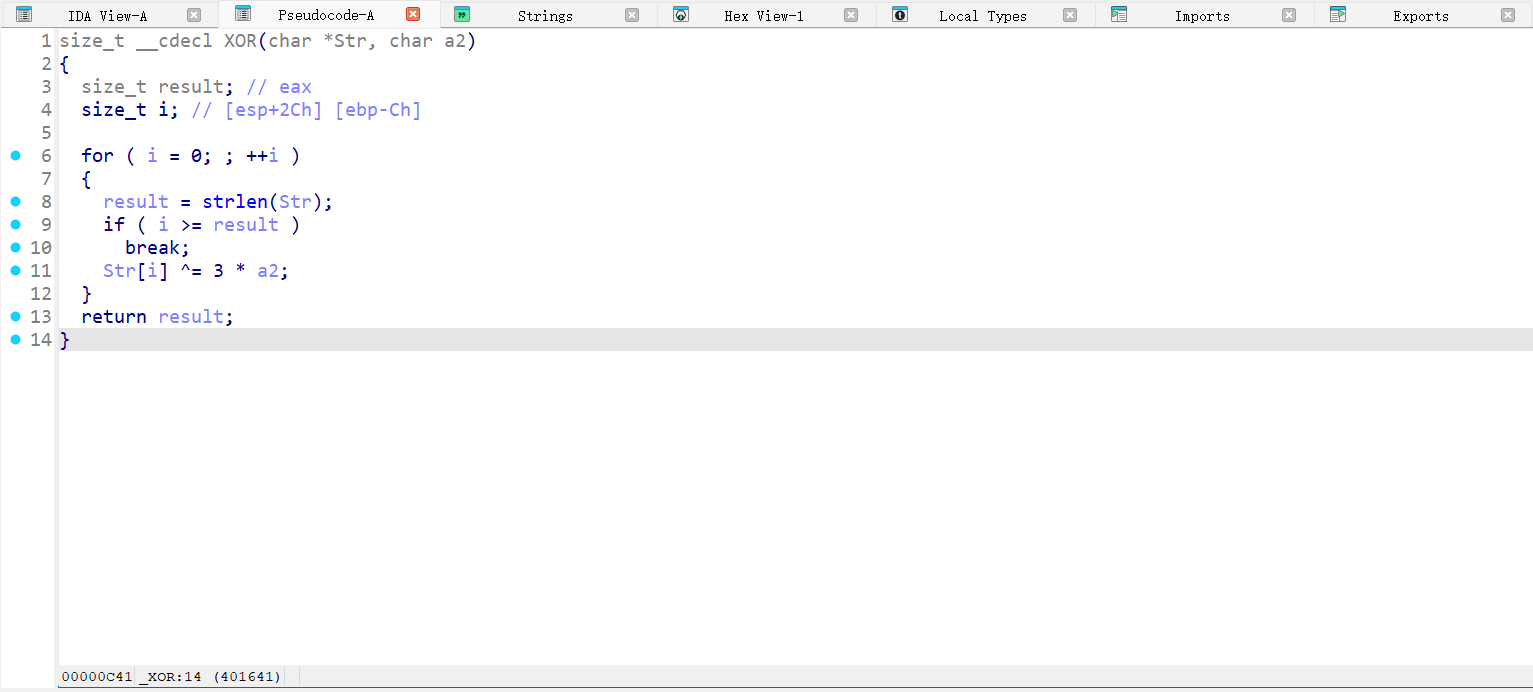
功能就是遍历字符,异或处理,再异或一遍就可以了
EXP:
1
2
3
4
5
6str='E`}J]OrQF[V8zV:hzpV}fVF[t'
flag=''
for i in range(len(str)):
flag+=chr(ord(str[i])^9)
print(flag)
# flag = 'NSSCTF{XOR_1s_3asy_to_OR}'(前缀做了改动)
[HUBUCTF 2022 新生赛]simple_RE
IDA打开,如图
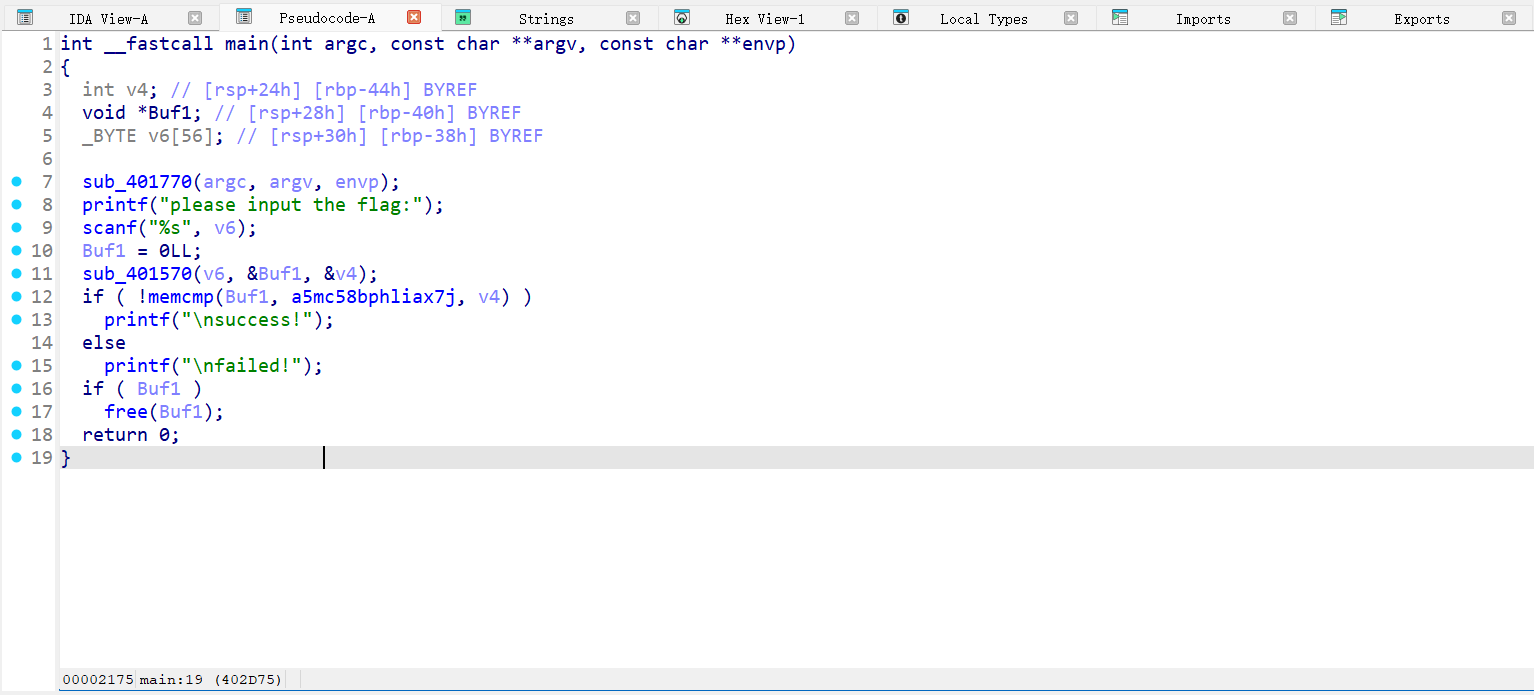
加密函数看起来逻辑很复杂,但是点开名字很奇怪的数组,发现一个编码表,可以推测是base64编码。
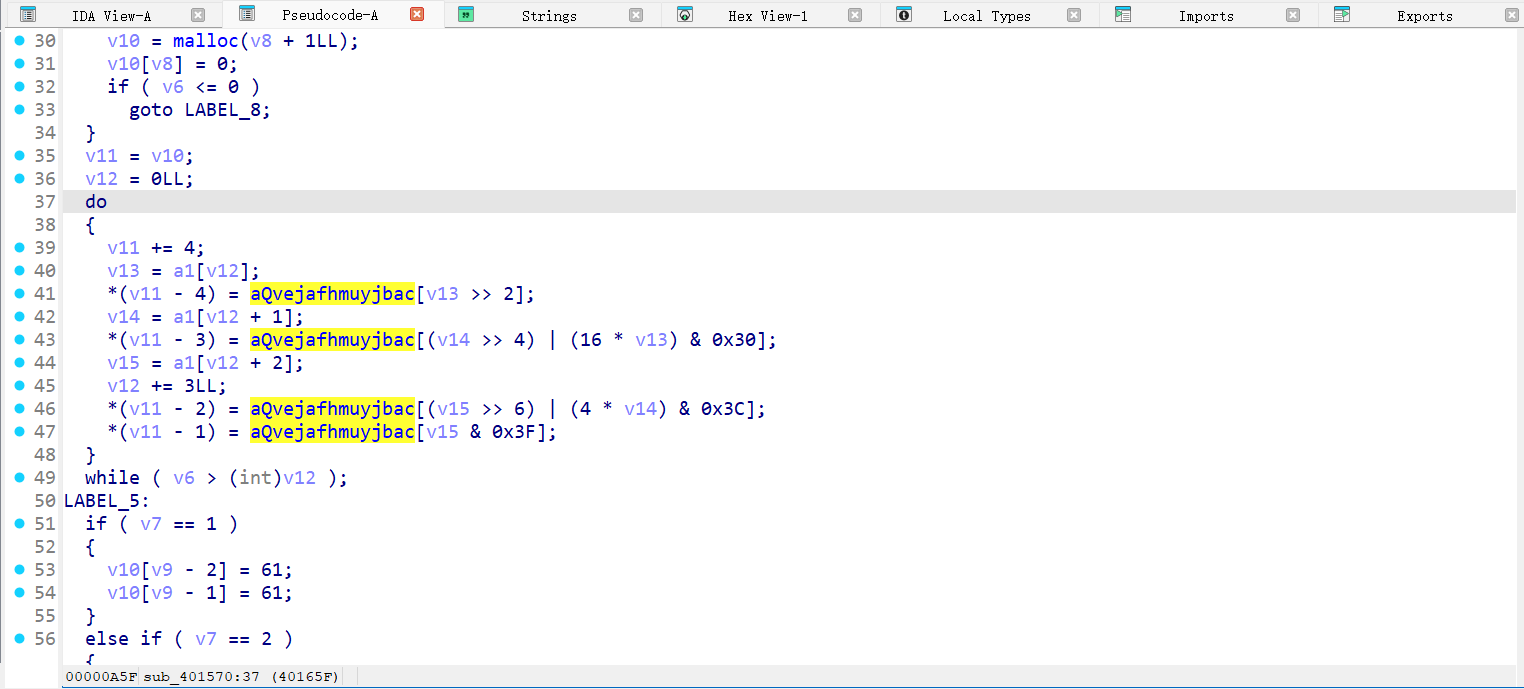

回过头看给的用来比较的字符串,基本可以确定是base64换表编码

找到了一个可以自定义编码表的python库cusbase64,可以用config指定编码表,这样就容易多了
EXP:
1
2
3
4
5
6
7import cusbase64
table='qvEJAfHmUYjBac+u8Ph5n9Od17FrICL/X0gVtM4Qk6T2z3wNSsyoebilxWKGZpRD'
enc='5Mc58bPHLiAx7J8ocJIlaVUxaJvMcoYMaoPMaOfg15c475tscHfM/8=='
b=cusbase64.CusBase64()
b.config(table)
b.decode(enc)
#flag = 'NSSCTF{a8d4347722800e72e34e1aba3fe914ae}'
[NSSCTF 2022 Spring Recruit]easy C
题目给的是c源文件,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33#include <stdio.h>
#include <string.h>
int main(){
char a[]="wwwwwww";
char b[]="d`vxbQd";
//try to find out the flag
printf("please input flag:");
scanf(" %s",&a);
if(strlen(a)!=7){
printf("NoNoNo\n");
system("pause");
return 0;
}
for(int i=0;i<7;i++){
a[i]++;
a[i]=a[i]^2;
}
if(!strcmp(a,b)){
printf("good!\n");
system("pause");
return 0;
}
printf("NoNoNo\n");
system("pause");
return 0;
//flag 记得包上 NSSCTF{} 再提交!!!
}分析逻辑,把输入的flag按字符先递增,再和2异或,得到的新数组应该和b一样。逆着来就是先异或再递减。
EXP:
1
2
3
4
5
6str='d`vxbQd'
flag=''
for i in str:
flag+=chr((ord(i)^2)-1)
print(flag)
#flag = 'NSSCTF{easy_Re}'
[NSSCTF 2022 Spring Recruit]easy Python
题目给的py源码,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import string
def encode(string,string2):
tmp_str = str()
ret = str()
bit_string_str = string.encode()
remain = len( string ) % 3
remain_str = str()
for char in bit_string_str:
b_char = (bin(char)[2:])
b_char = '0'*(8-len(b_char)) + b_char
tmp_str += b_char
for i in range(len(tmp_str)//6):
temp_nub = int(tmp_str[i*6:6*(i+1)],2)
ret += string2[temp_nub]
if remain==2:
remain_str = tmp_str[-4:] + '0'*2
temp_nub = int(remain_str,2)
ret += string2[temp_nub] + "="
elif remain==1:
remain_str = tmp_str[-2:] + '0'*4
temp_nub = int(remain_str,2)
ret += string2[temp_nub] + "="*2
return ret.replace("=","")
res = encode(input(),string.ascii_uppercase+string.ascii_lowercase+string.digits+'+/')
if res == "TlNTQ1RGe2Jhc2U2NCEhfQ":
print("good!")
else:
print("bad!")细细一看,encode()里面有加“=”的操作,并且使用的string2是字母大小写+数字+’+/‘,推测是base64,但是注意到encode()返回的时候把“=”替换成了“”,也就是删除了“==”,所以要把后面用于比较的也就是加密后的字符串加上“=”
EXP:
1
2
3
4
5import pybase64
str='TlNTQ1RGe2Jhc2U2NCEhfQ=='
flag=pybase64.b64decode(str)
print(flag)
#flag = 'NSSCTF{base64!!}'
[SWPUCTF 2021 新生赛]fakerandom
依旧是Py源码:
1
2
3
4
5
6
7
8
9
10
11
12
13import random
flag = 'xxxxxxxxxxxxxxxxxxxx'
random.seed(1)
l = []
for i in range(4):
l.append(random.getrandbits(8))
result=[]
for i in range(len(l)):
random.seed(l[i])
for n in range(5):
result.append(ord(flag[i*5+n])^random.getrandbits(8))
print(result)
# result = [201, 8, 198, 68, 131, 152, 186, 136, 13, 130, 190, 112, 251, 93, 212, 1, 31, 214, 116, 244]逻辑就是,用生成的伪随机数来异或flag的特定位。异或可逆,已知种子,伪随机数可以确定。所以只需要在源码的基础上稍作改动,把result和flag的位置调换一下就可以了
EXP:
1
2
3
4
5
6
7
8
9
10
11
12
13import random
flag = ''
result = [201, 8, 198, 68, 131, 152, 186, 136, 13, 130, 190, 112, 251, 93, 212, 1, 31, 214, 116, 244]
random.seed(1)
l = []
for i in range(4):
l.append(random.getrandbits(8))
for i in range(len(l)):
random.seed(l[i])
for n in range(5):
flag+=chr(result[i*5+n]^random.getrandbits(8))
print(flag)
#flag = 'NSSCTF{FakeE_random}'
[HNCTF 2022 Week1]X0r
IDA打开,main函数如下:
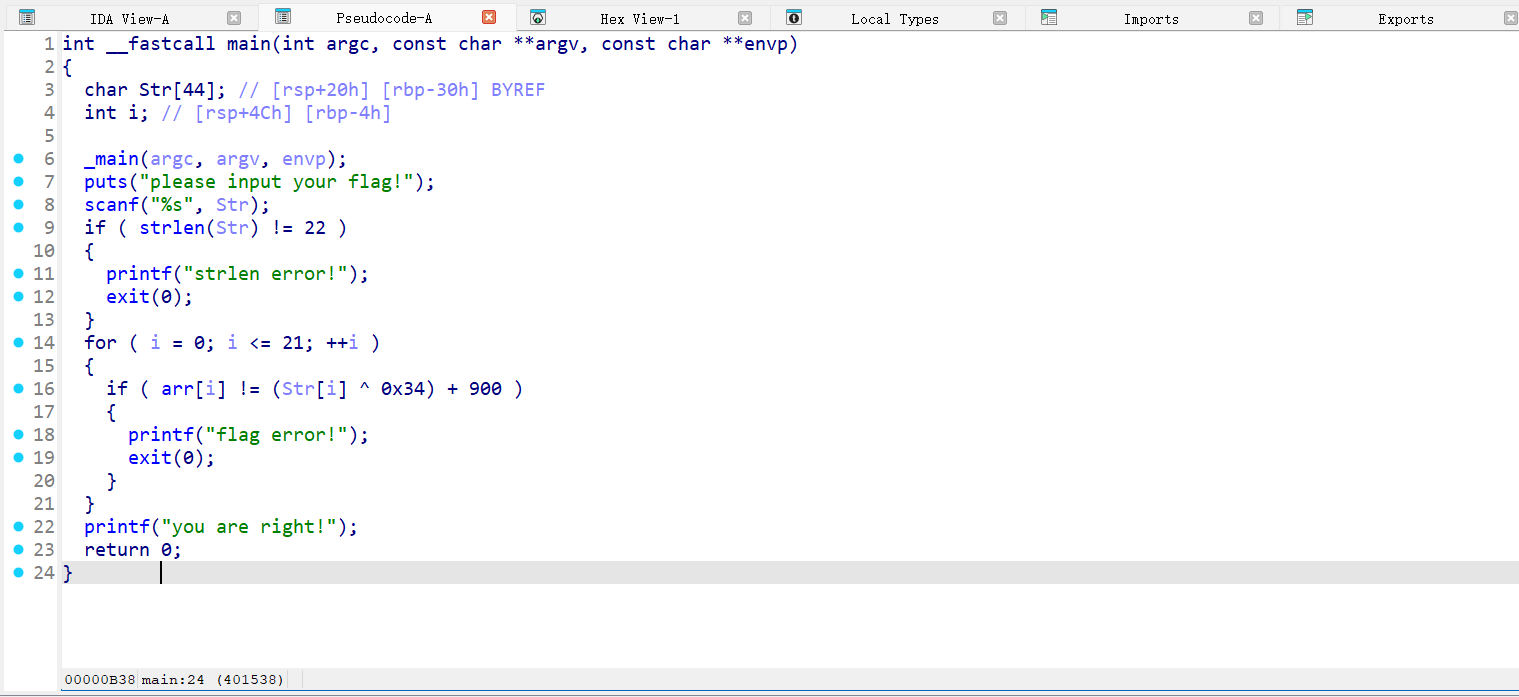
可以看出,逻辑就是对输入的字符串按字符异或处理,最后与给定的arr比较
EXP:
1
2
3
4
5
6arr=[0x000003FE, 0x000003EB, 0x000003EB, 0x000003FB, 0x000003E4, 0x000003F6, 0x000003D3, 0x000003D0, 0x00000388, 0x000003CA, 0x000003EF, 0x00000389, 0x000003CB, 0x000003EF, 0x000003CB, 0x00000388, 0x000003EF, 0x000003D5, 0x000003D9, 0x000003CB, 0x000003D1, 0x000003CD]
flag=''
for i in range(0,len(arr)):
flag+=chr((arr[i]-900)^0x34)
print(flag)
flag = 'NSSCTF{x0r_1s_s0_easy}'
[HGAME 2023 week1]easyenc
IDA打开,main函数如图
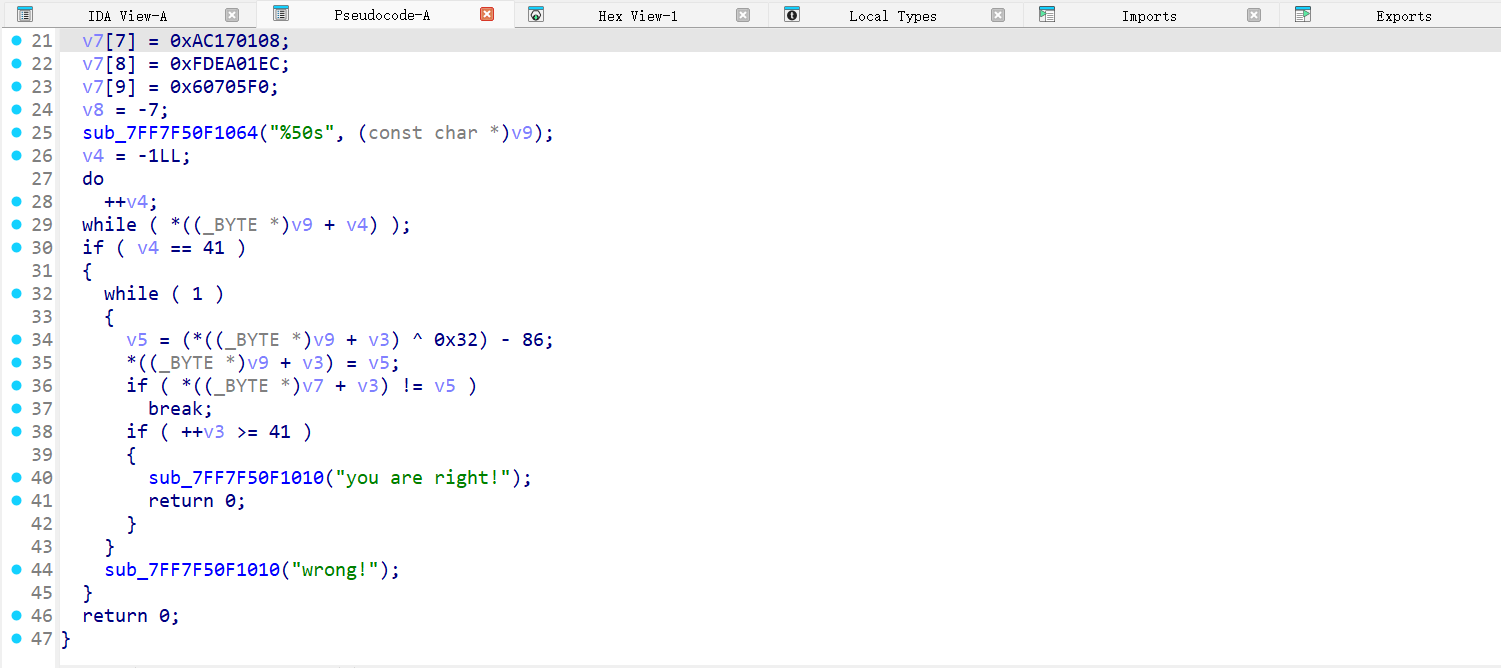
可以看到逻辑就是先遍历出输入字符串的长度( * ( ( _BYTE *) v9 + v4 )这样的格式可以看成:v9[v4],算是一种经验吧)然后循环对输入的字符串按字符进行运算,最后与给定的数据比较。
难点在于,给的是10个元素的数组,而输入的字符串却要求是41个字符。看来V7的格式不是很对,要把这么多位的数据进行划分才行。v7是DWORD类型,而参与运算的v9用的是BYTE类型,1DWORD=4BYTE,要把v7的数分成4部分,这里的数据不好提取,可以直接丢给AI。当然手动复制也可以。
EXP:
1
2
3
4
5
6
7
8
9
10
11
12
13buf=[0x9FDFF04,0xB0F301,0xADF00500,0x5170607,0x17FD17EB,0x1EE01EA,0xFA05B1EA,0xAC170108,0xFDEA01EC,0x60705F0]
flag=''
buf1 = []
for num in buf:
bytes_data = num.to_bytes(4, byteorder='little')
for byte in bytes_data:
buf1.append(hex(byte))
#print(buf1)
for num in buf1:
tmp=((int(num,16)+86)^0x32)&0xff
flag+=chr(tmp)
print(flag)
#flag = 'NSSCTF{4ddit1on_is_a_rever5ible_0peration}'(修改了前缀)当然得多学一点,所以手搓v7,找DS问一下怎么处理数据,得到如上的方法。
用to_bytes把v7的数转成字节形式,byteorder指定了小端序,然后hex转换成十六进制数存入新列表。至于为什么要转成十六进制数,和下面的代码有关。
然后用新列表的元素进行逆运算。因为直接使用这些元素会被判成字符,所以前面先转成十六进制数,再用int转成十进制数,这样就可以正常运算了
最后还要&0xff,因为逆出来的数据有点超出ascii码范围了
还有就是,这样得出来的flag其实缺了一个“ } ”。回头看反编译的代码,那个未命名的用来输入v9的实际上不是纯粹的scanf那样的函数。里面有个FILE指针,推测是读文件的函数。所以读取的内容结尾按道理会有’\0’。但是,加上了’\0’算出来的flag也没有’ } ‘。所以,凭常识加上’ } ‘。
Re:从0到1的脚本之路